
项目介绍:
这是一个关于NLP的项目,会根据输入的文章内容提炼出新闻摘要。
前端:
前端页面部署在服务器http://www.wuqin.tech/wq/上
采用bootstrap快速布局,自适应移动和PC端
使用Jquery的库,ajax发送http请求。
存在跨域请求,设置了RequestHeader(“Access-Control-Allow-Origin”, “*”)
文本预处理
训练词向量需要用到两个语料库:维基百科中文语料库 和 汉语新闻语料库。
维基百科文本预处理
- 文本读取:wikiextractor,存储为json,每个生成的文件中,每行对应一个以 JSON 格式存储的词条,格式如下:
{“id”: xxx, “url”: xxx, “title”: xxx, “text”: xxx}
其中text的值对应的是该词条的内容,即我们需要的数据。
文本清洗:去除特殊符号,数字,英文,以及繁体转简体(使用opencc-python-reimplemented 库),提取token
汉语新闻语料库预处理
文本清洗:去除特殊符号,数字,英文,提取token
使用Gensim进行词向量训练
测试词向量的语义相似性(以‘数学’为例)和词向量的线性关系(以analogy(‘中国’, ‘汉语’, ‘美国’) 和analogy(‘美国’, ‘奥巴马’, ‘美国’) 为例):
词向量的可视化:
- 使用t-sne进行高维向量的可视化
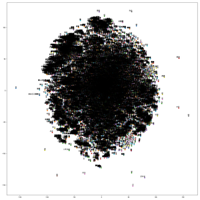
全部词向量可视化
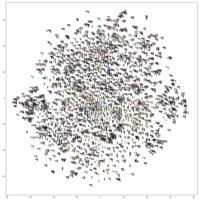
只显示词频大于10000 的词
参数调优
- SIF论文中介绍的算法,核心参数为词向量权重表达式a/(a+p(w))中的a值
- 调参结果评判标准:选定人工标注好的句子相似度数据集,用SIF算法的到句子的向量,用余弦距离作为句子相似度,将得到的结果与人工标注的结果比较,pearsonr值越大说明越接近标注(真实)值。使用不同a值进行上述运算,比较效果。
- 调参范围:根据论文作者经验,最优值通常为1e-3或1e-4,因此决定在此范围内做搜索,如果遇到极值点,则在极值点附近用更小的步进进行搜索。
- 选用数据集: https://github.com/IAdmireu/ChineseSTS
参数调整记录
- 首先以1e-4为步进,结果如下:

在所选定区间内,效果呈单调递减趋势,固不再进行进一步搜索,使用1e-4为最后参数。
调参代码地址: https://github.com/mengzeyu/nlp-project-01/blob/master/parameter_optimization.ipynb
后端restful服务
使用flask-restful编写,简洁,部署快捷。
只提供数据,做到前后端分离,方便共同开发。
在算法函数的基础上,添加一些异常情况处理(如句子中的词语都找不到对应词向量时的处理),保证服务稳定性
代码地址:https://github.com/mengzeyu/nlp-project-01/blob/master/restful.py
项目的优点
- 使用word2vec 词向量模型,采用维基百科中文语料库+汉语新闻语料库进行词向量的训练
- 使用普林斯顿大学提出来的SIF方法,进行句子的向量化
- 通过计算句子向量与标题向量、全文向量的余弦相似和相关系数得出句子与全文的相关度
- 采用KNN的思想对句子的相关度与周围其他句子的相关度进行加权求和平滑,使句子之间变得更通顺
- 算法模型实现封装性良好,提供动态调整参数的接口
- 提供良好的可视化页面
模型分析报告
算法模型在SIF算法的权值a为1e-4,使用余弦相似度计算句子相关度,句子相关度KNN平滑窗口为1(即句子与前后一个句子的相关度加权求和)情况下,能够正确对输入文本内容进行摘要,输出流畅通顺的摘要内容。